심층 강화학습 인 액션의 chater4내용을 나름대로 이해한내용을 바탕으로 정리해보았습니다
부정확한 내용이 있다면 피드백 부탁드립니다
정책망이 뭐에요?
정책망은 상태를 받고 모든 가능한 동작들의 확률분포를 돌려주는 함수
최종적으로 동작을 선택하는 방식은 다음과 같다
정책망이 가능한 동작 4가지에대해 확률분포를 예측한다 (각 동작의 확률을 모두 더하면 1이된다)
만약 2번 동작의 보상이 가장 클것이라고 예측한다면 2번의 확률이 가장높다
이상태에서 확률분포에 따라 모델은 동작을 선택을 하게된다
2번 동작이 뽑힐 확률이 가장 높겠지만 다른 동작이 뽑힐수도있다
게임소개
CartPole
강화학습에서 많이 사용되는 클래식한 환경중 하나이다 막대기와 수래로 구성되어있다

목표: 막대가 넘어지지않고 수레를 제어하여 막대를 가능한 오랫동안 수직으로 유지하는것
상태: 막대의 수평 위치, 수레의 속도, 막대의 각도, 막대의 각속도
액션: 왼쪽과 오른쪽
게임오버: 막대의 각도가 허용범위를 벗어나는경우, 수레의 위치가 허용범위를 벗어나는 경우
코드구현
이게임의 목적은 최대한 오래버티는것이다
만약 cartpole게임이 60초만에 끝났다고 해보자
따라서 게임오버가 되기직전 마지막 움직임은 잘못된 행동이었다고 간주할수있다
반대로 게임시작 최초의 움직임은 좋은 행동이었다고 간주할수있다
따라서 보상을 시간에 경과함에 따라 점점 적게주는 쪽으로 구현하는것은 나쁘지않은 선택이다
(더 나은 방법이 있을것같긴하다)
다만 지금 움직임이 좋은 움직임인지 나쁜 움직임인지는
움직이고 나서 바로 알수없다 게임이 끝나고나야 알수있다
따라서 움직임 이후 실시간 학습이 진행되는 온라인학습법으로 구현할수없다
import numpy as np
import torch
import gym
from matplotlib import pyplot as pltenv = gym.make("CartPole-v0")l1 = 4 #A
l2 = 150
l3 = 2 #B
model = torch.nn.Sequential(
torch.nn.Linear(l1, l2),
torch.nn.LeakyReLU(),
torch.nn.Linear(l2, l3),
torch.nn.Softmax(dim=0) # 열발향으로 진행된다
)
learning_rate = 0.009
optimizer = torch.optim.Adam(model.parameters(), lr=learning_rate)def loss_fn(preds, r): #A
return -1 * torch.sum(r * torch.log(preds)) #B
시간이 갈수록 보상이 줄어드는것을 구현한 코드이다 gamma를 낮게 설정해서
보상의 감소를 더 극적으로 만들수도 있다
def discount_rewards(rewards, gamma=0.99):
lenr = len(rewards)
disc_return = torch.pow(gamma,torch.arange(lenr).float()) * rewards #A
disc_return /= disc_return.max() # 정규화를 통해 0~1사이의 값을 갖게된다
return disc_return
MAX_DUR = 200
MAX_EPISODES = 300
gamma = 0.99
score = [] # episode별 게임 지속시간이 저장된다
expectation = 0.0
for episode in range(MAX_EPISODES):
curr_state = env.reset()
done = False
transitions = [] #B
for t in range(MAX_DUR): #C
act_prob = model(torch.from_numpy(curr_state).float()) #D
action = np.random.choice(np.array([0,1]), p=act_prob.data.numpy()) #E
prev_state = curr_state
curr_state, _, done, info = env.step(action) #F
transitions.append((prev_state, action, t+1)) #G
if done: #H
break
ep_len = len(transitions) #I
score.append(ep_len)
reward_batch = torch.Tensor([r for (s,a,r) in transitions]).flip(dims=(0,)) #J
disc_returns = discount_rewards(reward_batch) #K
state_batch = torch.Tensor([s for (s,a,r) in transitions]) #L
action_batch = torch.Tensor([a for (s,a,r) in transitions]) #M
pred_batch = model(state_batch) #N
prob_batch = pred_batch.gather(dim=1,index=action_batch.long().view(-1,1)).squeeze() #O
loss = loss_fn(prob_batch, disc_returns) # 크로스엔트로피손실을 구한다
optimizer.zero_grad()
loss.backward()
optimizer.step()
코드가 크게 복잡하진않아서 잘모르겠는부분은 print해보면서 진행하면 아마 이해가 될것이다
내가 조금 햇갈렸던 부분을 같이 보도록하자
한 게임이 종료되면 게임의 모든 상태에 대해서 다시한번 확률분포 예측을 한다
pred_batch = model(state_batch)다만 Softmax(dim=0)이기때문에 형태가 독특하다
pred_batch: tensor([[5.5923e-02, 1.2456e-02],
[2.3605e-02, 2.5844e-02],
[5.4468e-02, 1.1697e-02],
[2.3399e-02, 2.4897e-02],
[5.1949e-03, 3.3675e-02],
...그래서 각 열을 더하면 1이다
prob_batch = pred_batch.gather(dim=1,index=action_batch.long().view(-1,1)).squeeze()
각 상태에서 실제로 취한 동작의 확률들만 모은다
prob_batch: tensor([0.0559, 0.0258, 0.0545, 0.0234, 0.0052...
그리고 실제로 취한 동작의 확률과 보상의 크로스엔트로피 손실을 구하게된다
당연한 말이지만 prob_batch는 disc_returns와 최대한 비슷해지는쪽으로 학습이 진행이 될것이다
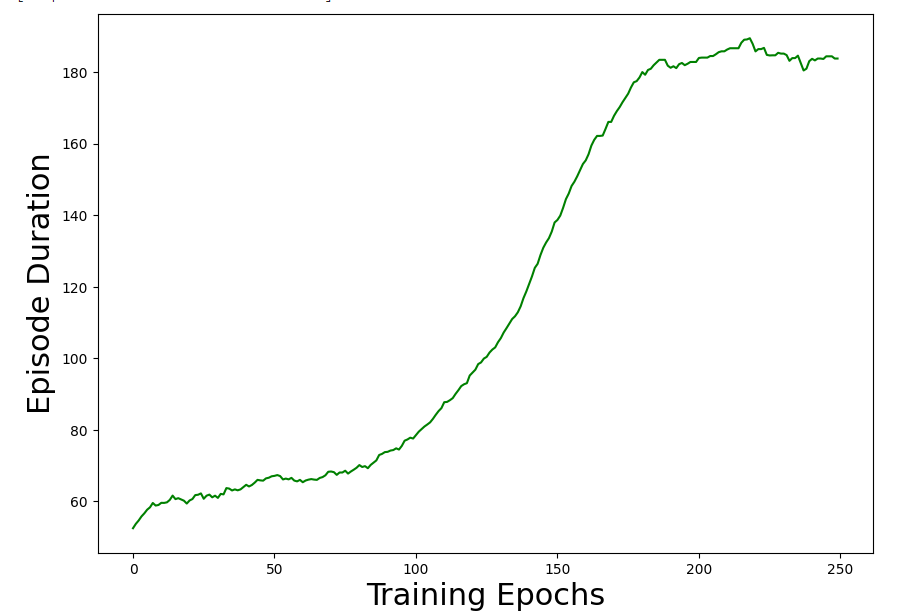
episode duration-training epochs 그래프를 보게되면
요런식으로 나온다
'공부 정리 > 강화 학습' 카테고리의 다른 글
| 마르코프 리워드 프로세스(Markov Reward Process, MRP) (0) | 2023.09.10 |
|---|---|
| [강화학습2]마르코프 프로세스(Markov Process) (0) | 2023.09.04 |
| [강화학습1]강화학습의 기본개념 이해 (0) | 2023.09.01 |
| 목표망(target network)이 있는 Q학습 (0) | 2023.03.18 |
| 파국적 망각 방지: 경험재현 (0) | 2023.03.13 |




댓글