 [강화학습3]마르코프 결정 프로세스(Markov Decision Process)
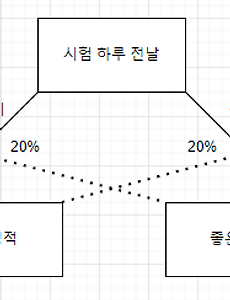
MDP의 정의 아래의 사진은 MDP를 도식화한 것이다 $$MDP \equiv (S, A, P, R,\gamma)$$ 마르코프 프로세스에 보상, 할인계수, 행동의 개념이 추가되면 마르코프 리워드 프로세스가 된다. 아까 마르코프 프로세스는 상태의 집합 $S$와 전이확률행렬$P$로 구성된 프로세스였다면, $MDP$를 정의하기 위해서는 보상함수$R$과 할인계수$\gamma$(감마), 행동의 집합$A$ 총 3가지 요소가 추가로 필요하다 $$MDP \equiv (S, A, P, R,\gamma)$$ 상태의 집합 $S$ $$S = \{s_0, s_1, s_2, \ldots, s_n\}$$ 가능한 상태들을 모두 모아놓은 집합이다. 액션의 집합 $A$ $$S = \{a_0, a_1, a_2, \ldots, a_n\}$$..
2023. 9. 24.
[강화학습3]마르코프 결정 프로세스(Markov Decision Process)
MDP의 정의 아래의 사진은 MDP를 도식화한 것이다 $$MDP \equiv (S, A, P, R,\gamma)$$ 마르코프 프로세스에 보상, 할인계수, 행동의 개념이 추가되면 마르코프 리워드 프로세스가 된다. 아까 마르코프 프로세스는 상태의 집합 $S$와 전이확률행렬$P$로 구성된 프로세스였다면, $MDP$를 정의하기 위해서는 보상함수$R$과 할인계수$\gamma$(감마), 행동의 집합$A$ 총 3가지 요소가 추가로 필요하다 $$MDP \equiv (S, A, P, R,\gamma)$$ 상태의 집합 $S$ $$S = \{s_0, s_1, s_2, \ldots, s_n\}$$ 가능한 상태들을 모두 모아놓은 집합이다. 액션의 집합 $A$ $$S = \{a_0, a_1, a_2, \ldots, a_n\}$$..
2023. 9. 24.








